知识蒸馏
Distillation知识蒸馏
知识蒸馏用于模型压缩,用一个已经训练好的模型A去教另一个模型B。又称为老师-学生模型。通常A比B强,B可以突破自我。

后面的矩阵[0.7,0.29,0.01]说明老师能够交给学生更多的东西:
[1,0,0] 就像标准答案,而 [0.7,0.29,0.01]
就是解析。
先介绍几个函数:
softmax
输出非负,0~1之间的概率分布
1
2
3
4
5
6
7
8
9
10
11
12
13def softmax(x):
x_exp = np.exp(x)
return x_exp / np.sum(x_exp)
print(softmax(output))
//增加了t temperature
def softmax(x,t):
x_exp = np.exp(x/t)
return x_exp / np.sum(x_exp)
print(softmax(output,5))可见t会使得概率分布更加平滑
log_softmax
输出全为负数
NLLLoss
输入:log_softmax(output),target
![]()
从NLLLoss中可以看出第三类最小,其实从
[1.2,2,3]的得分中也可以看出第三类得分最高。CE交叉熵
![]()
其中
qk是神经网络认为第k类的概率,并且是经过softmax的了。确实只有当
py=1的时候,就可以简化为\(-log (q_y)\)
![]()
可以发现CE可以一步到位。
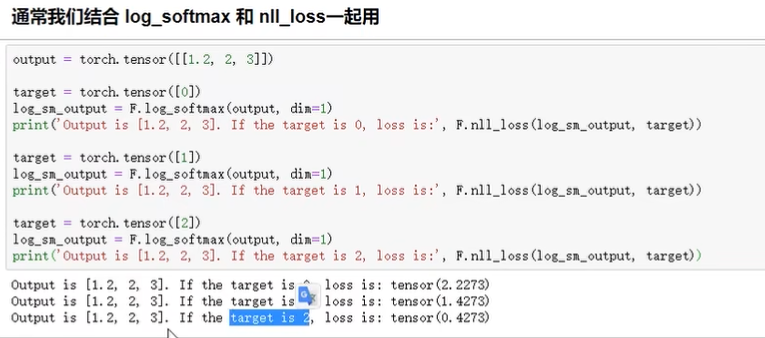

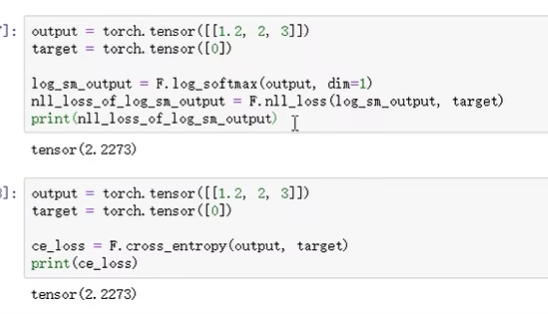
softmax + nllloss = ce
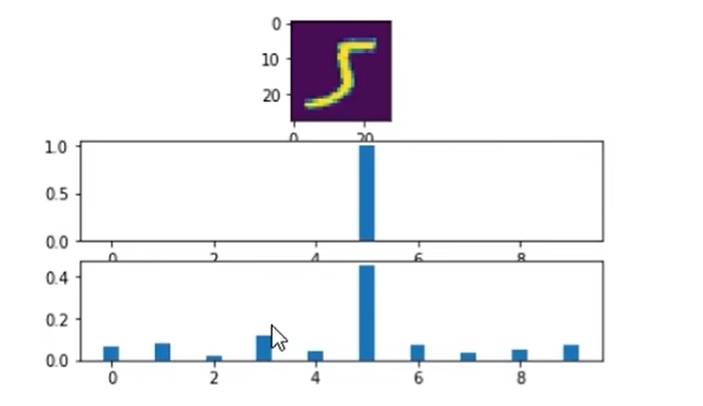
上图:t = 1;下图:t = 10;
可见通过设置相应的temperature将暗部特征都蒸馏出来了.(其实就是将概率分布更加平滑)
训练Teacher-Student网络
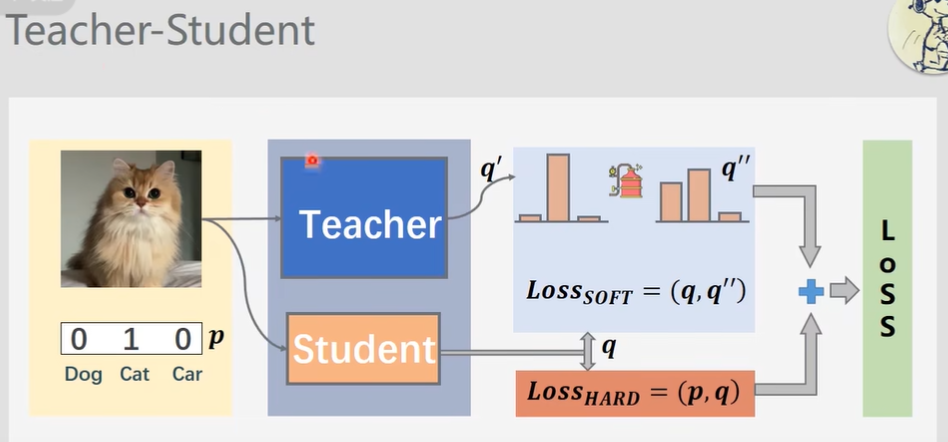
说明:
p 是标准答案
q 是学生的答案
q' 是老师的带有解析的答案
q''
是将老师的带有解析的答案经过蒸馏之后的结果(发现了这只猫实际上有点像狗狗)
Loss(p,q) 是Hard Loss
因为p是one-hot 的
Loss(q,q'') 是 soft Loss
最后minimize两个Loss之和

KLDivLoss计算的是soft loss,cross_entropy计算的是hard loss
结果:
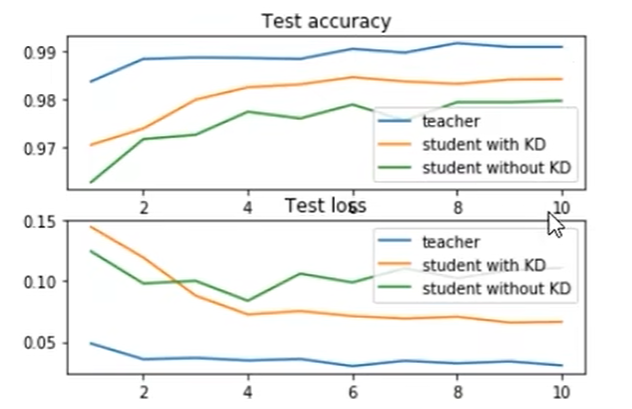

prior 是先验知识,人为地加入。而KD
不是人为地加入,而是通过一个老师模型来加入一些限制。