具体要求
对输入的testfile.txt
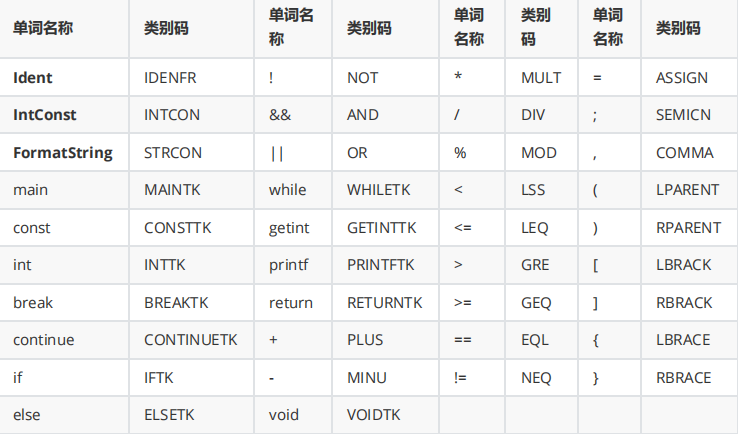
文件逐行解析,并输出对应的单词名称和类别码,具体输出要求如下表所示:
![]()
输入输出要求具体如下所示:
输入:
1
2
3
4
5
| const int a = 0;
int main(){
int f = 0;
return 0;
}
|
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| 1 CONSTTK const
1 INTTK int
1 IDENFR a
1 ASSIGN =
1 INTCON 0
1 SEMICN ;
2 INTTK int
2 MAINTK main
2 LPARENT (
2 RPARENT )
2 LBRACE {
3 INTTK int
3 IDENFR f
3 ASSIGN =
3 INTCON 0
3 SEMICN ;
4 RETURNTK return
4 INTCON 0
4 SEMICN ;
5 RBRACE }
|
其中第一列为行号,第二列为类别码,第三列为token.
实现方法
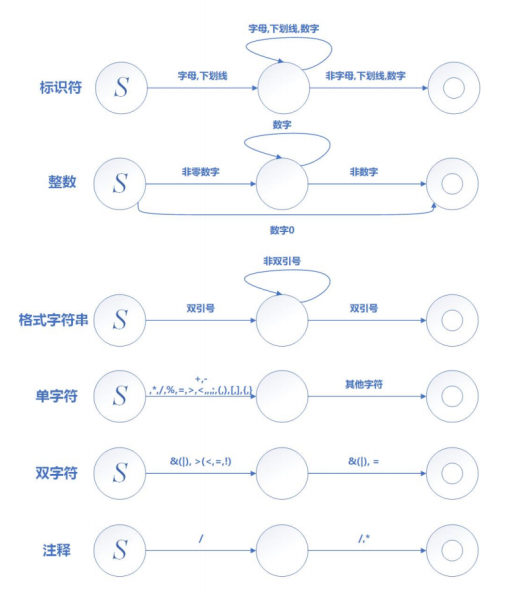
通过有限自动机DFA实现对输入序列进行处理:
![]()
具体实现
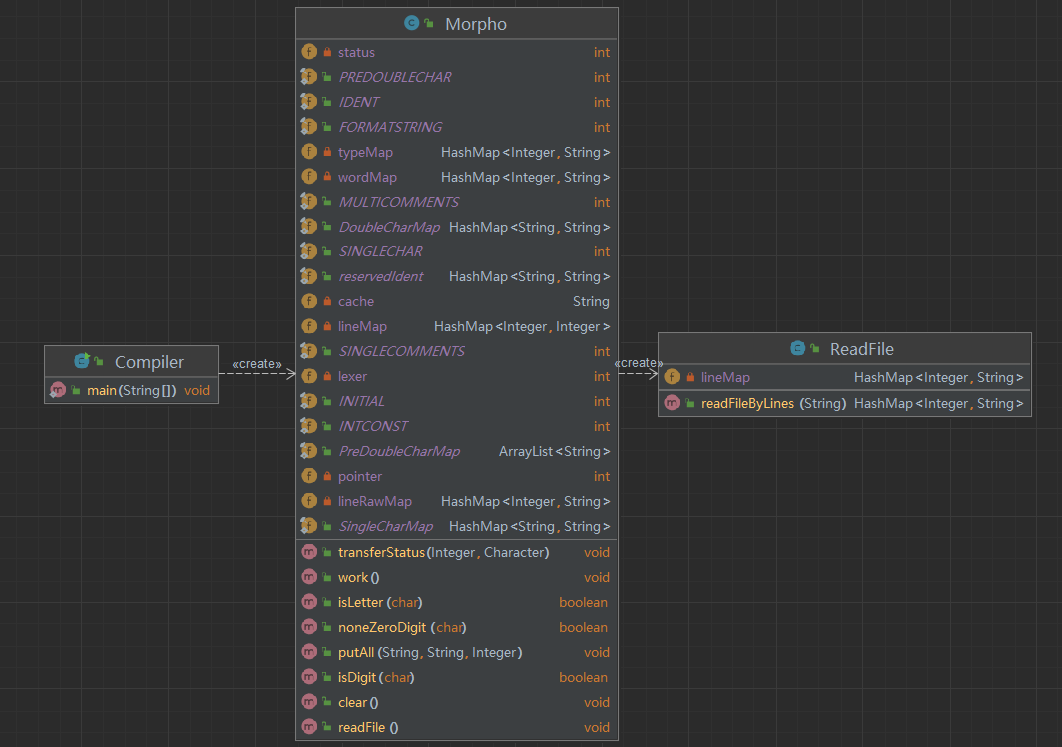
词法分析部分的类的构建我只用了一个Morpho,从Compiler
程序进入Morpho 类中,最后Morpho
能够输出对应的行号、类别码、token.
![]()
Morpho词法分析类:
HashMap<Integer,String> lineRawMap:用于存储读入文件,key为行号,value为每行的内容,通过readFile读入
HashMap<Integer,String> typeMap
:存储类别码
HashMap<Integer,String> wordMap
:存储token
HashMap<Integer,String> lineMap
:存储每个token对应的行号
lexer:输出token的总数量
(实际上是通过lexer同时维护上述三个hashmap,同增同减)
int status :当前状态
String cache:缓存器
pointer:指针,用于扫描当前行
INITIAL,IDENT,INTCONST,FORMATSTRING,SINGLECHAR,SINGLECOMMENTS,MULTICOMMENTS,PREDOUBLECHAR:状态的中间形式
以上就是对这个类的属性的解释。
其中PREDOUBLECHAR指的是识别到&&和||的第一个字符时的状态。
方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| public void work() throws IOException {
readFile();
for (Map.Entry<Integer, String> entry : lineRawMap.entrySet()) {
this.pointer = 0;
if (status == SINGLECOMMENTS) {
this.status = INITIAL;
cache = "";
}
if(status == MULTICOMMENTS) {
cache = "";
}
if(cache.length() != 0) {
transferStatus(entry.getKey() - 1,' ');
cache = "";
status = INITIAL;
this.pointer = 0;
}
while (this.pointer < entry.getValue().length()) {
transferStatus(entry.getKey(), entry.getValue().charAt(this.pointer));
pointer++;
}
}
while(status != INITIAL) {
transferStatus(lineRawMap.size(),' ');
}
File f=new File("output.txt");
f.createNewFile();
FileOutputStream fileOutputStream = new FileOutputStream(f);
PrintStream printStream = new PrintStream(fileOutputStream);
System.setOut(printStream);
ArrayList<Token> tokens = new ArrayList<>();
for(int i = 0;i < typeMap.size();i ++) {
System.out.println(lineMap.get(i)+" "+typeMap.get(i) + " " + wordMap.get(i));
Token token = new Token(typeMap.get(i),wordMap.get(i),lineMap.get(i));
tokens.add(token);
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
| public void transferStatus(Integer line, Character ch) {
if (this.status == INITIAL) {
if (ch == ' ') this.status = INITIAL;
else if (isLetter(ch) || ch == '_') {
this.status = IDENT;
this.cache += ch;
}else if (isDigit(ch)) {
this.status = INTCONST;
this.cache += ch;
} else if (ch == '"') {
this.status = FORMATSTRING;
cache += ch;
} else if (SingleCharMap.containsKey(ch+"")) {
this.status = SINGLECHAR;
cache += ch;
} else if(PreDoubleCharMap.contains(ch+"")) {
this.status = PREDOUBLECHAR;
cache += ch;
}
} else if (this.status == IDENT) {
if (isLetter(ch) || ch == '_' || isDigit(ch)) {
this.status = IDENT;
this.cache += ch;
} else {
if (reservedIdent.containsKey(cache)) {
putAll(reservedIdent.get(cache), cache, line);
} else {
putAll("IDENFR", cache, line);
}
clear();
}
} else if (this.status == INTCONST) {
if (isDigit(ch)) {
this.status = INTCONST;
cache += ch;
} else {
putAll("INTCON", cache, line);
clear();
}
} else if (this.status == FORMATSTRING) {
if (ch != '"') {
this.status = FORMATSTRING;
cache += ch;
} else {
putAll("STRCON", cache+ch, line);
clear();
pointer++;
}
} else if (this.status == SINGLECHAR) {
if (DoubleCharMap.containsKey(cache + ch)) {
putAll(DoubleCharMap.get(cache + ch), cache + ch, line);
cache = "";
this.status = INITIAL;
} else if ((cache+ch).equals("//")) {
this.status = SINGLECOMMENTS;
cache = "";
} else if ((cache + ch).equals("/*")) {
this.status = MULTICOMMENTS;
cache = "";
} else {
putAll(SingleCharMap.get(cache), cache, line);
clear();
}
} else if (this.status == PREDOUBLECHAR){
if (DoubleCharMap.containsKey(cache + ch)) {
putAll(DoubleCharMap.get(cache + ch), cache + ch, line);
cache = "";
this.status = INITIAL;
}
}else if (this.status == SINGLECOMMENTS) {
cache = "";
} else if (this.status == MULTICOMMENTS) {
if(cache.length() >= 1 && cache.charAt(cache.length() - 1) == '*' && ch == '/') {
cache = "";
this.status = INITIAL;
}else {
this.status = MULTICOMMENTS;
cache += ch;
}
} else {
this.status = INITIAL;
}
}
|
1
2
3
4
5
| public void clear() {
this.cache = "";
this.status = INITIAL;
this.pointer--;
}
|
1
2
3
4
5
6
| public void putAll(String type, String word, Integer line) {
this.typeMap.put(lexer, type);
this.wordMap.put(lexer, word);
this.lineMap.put(lexer, line);
lexer++;
}
|
注意clear()函数出现在每次状态转换完,因为是当前字符使得当前状态结束,所以pointer应该回退一格,使得当前状态重新变为INITIAL准备好了之后,再重新处理这个字符。
但是有个特殊情况FormatString,这个状态结束是遇到了"。所以这个双引号也要加入到输出中,所以clear之后,pointer++,否则这个双引号要重新判断一遍了。
总结一下:
就是要把cache+ch都加入进去的时候,clear()完之后要让pointer++,其余状态转换之后直接clear()即可.
注意细节
PREDOUBLECHAR状态时,如果ch+cache在DoubleCharMap中,则放入;而且,在SINGLECHAR
状态时,如果ch+cache在DoubleCharMap
中,则同样也要加入(专指==等双字符)。所以总共有两条途径要用到DoubleCharMap