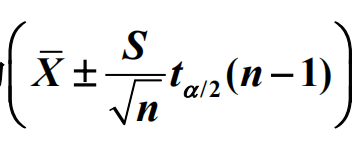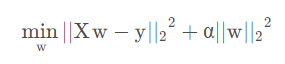d = np.array([1050,1100,1120,1250,1280]) n = len(d) # 计算均值 xb = d.mean() # 计算标准差 s = d.std(ddof=1) # 计算样本均值的标准差 sm = sem(d) a = 0.10 ta = t.ppf(1-a/2,n-1) L = [xb-sm*ta,xb+sm*ta] print(L)
结果
1
L=[1064.89955998421, 1255.10044001579]
习题2-1
构建样本点
储存在points矩阵中。
1 2 3 4 5 6 7 8 9 10 11
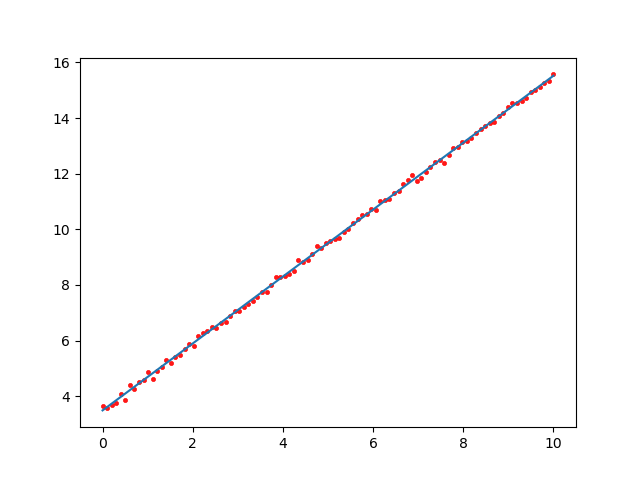
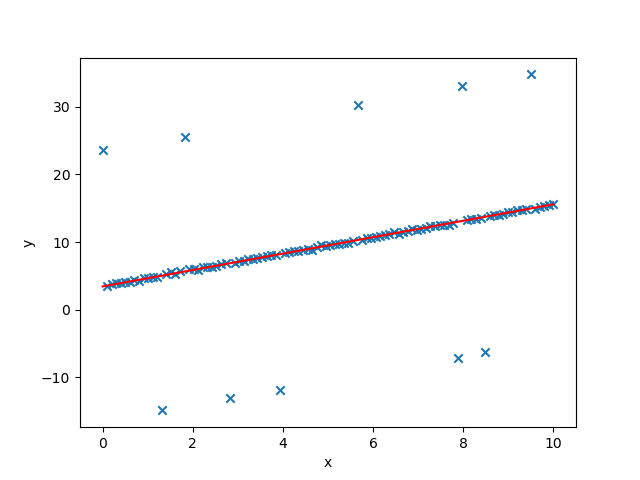
x=np.linspace(0,10,N) a = 1.2 b = 3.5 y0 = a * x + b y_noise = [np.random.normal(0, 0.1) + y for y in y0] points = [] i = 0 for x0 in x : points.append([x0,np.random.normal(0, 0.1) + a * x0 + b]) i = i + 1 points = np.array(points)
leastsq拟合
先尝试用sklearn的leastsq拟合(此方法用的是最小二乘)得到结果作为验证。
1 2 3 4 5
p0 = np.random.randn(2) # t=[a,b] fun = lambda t, x : t[0] * x + t[1] err = lambda t, x, z: fun(t,x) - z p2 = leastsq(err, p0, args=(x,y_noise))[0]
结果:
1 2 3
leastsq拟合: [1.203308453.48951605] a = 1.20330845 b = 3.48951605
defcomputer_cost(w, b, points): total_cost = 0 M = len(points) # 逐点计算平方损失误差,然后求平均数 for i inrange(M): x = points[i][0] y = points[i][1] total_cost += (y - w * x - b) ** 2 # 取平均 return total_cost / M
最小绝对偏离估计
损失函数:
\[
f=\sum|sx_j+b_j-y_j|
\]
1 2 3 4 5 6 7 8 9 10
defcomputer_cost_B(w, b, points): total_cost = 0 M = len(points) # 逐点计算平方损失误差,然后求平均数 for i inrange(M): x = points[i][0] y = points[i][1] total_cost += abs(y - w * x - b) # 取平均 return total_cost / M
最小最大偏离估计
损失函数:
\[
f=max|sx_j+b_j-y_j|
\]
1 2 3 4 5 6 7 8 9 10 11 12 13
defcomputer_cost_C(w, b, points): total_cost = 0 M = len(points) # 逐点计算平方损失误差,然后求平均数 maxCost = 0 for i inrange(M): x = points[i][0] y = points[i][1] ifabs(y - w * x - b) > maxCost: maxCost = abs(y - w * x - b) else: continue return maxCost
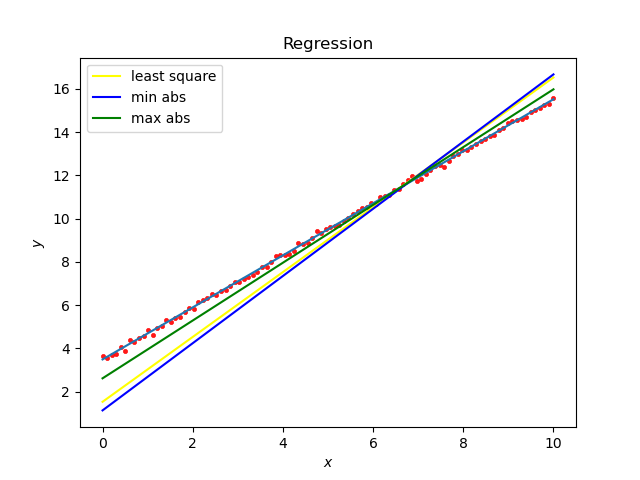
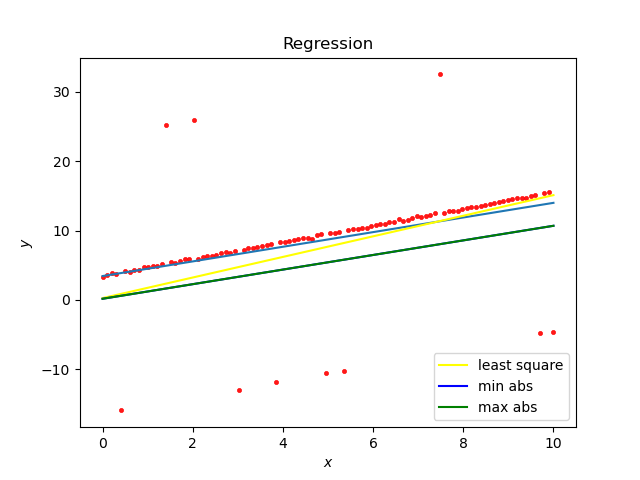
leastsq拟合: [1.203308453.48951605] 最小二乘法: a is : 1.4119904872895737 b is : 2.1132899832906866 cost is : 0.49050095850618497 最小绝对偏离估计: a is : 1.3806101062114216 b is : 2.321991385922966 cost is : 0.49535272270004677 最小最大偏离估计: a is : 1.2607599489963919 b is : 3.119078452972342 cost is : 0.4972349489227139
结果
1 2 3 4 5 6 7 8 9 10 11 12 13
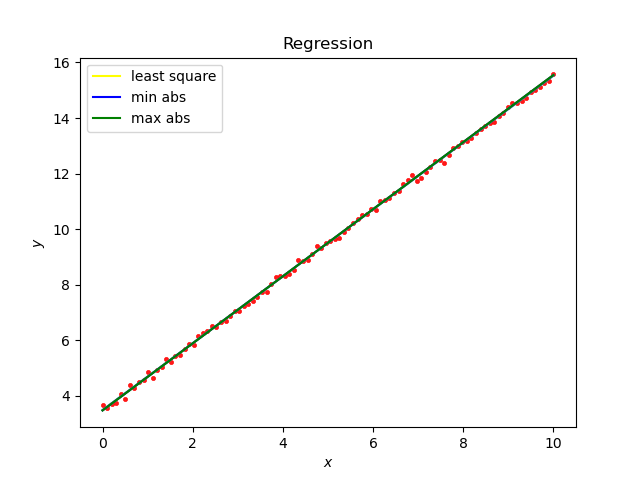
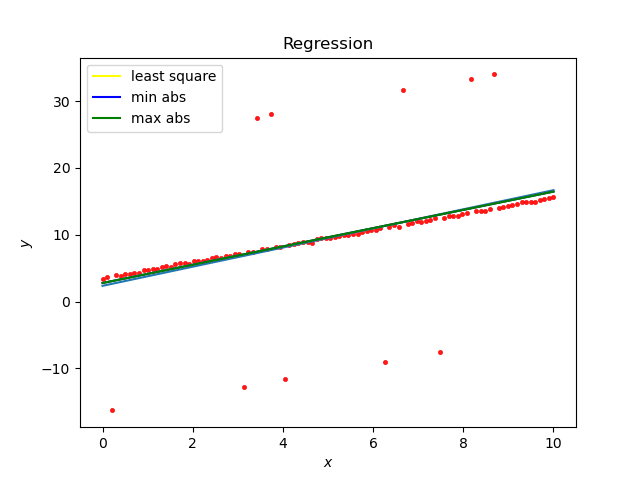
leastsq拟合: [1.203308453.48951605] 最小二乘法: a is : 1.207278913671576 b is : 3.4747646079211276 cost is : 0.008561611307963823 最小绝对偏离估计: a is : 1.207278913671576 b is : 3.4747646079211276 cost is : 0.07193785933645268 最小最大偏离估计: a is : 1.207278913671576 b is : 3.4747646079211276 cost is : 0.25574581839753696
leastsq拟合: [1.357073973.52990959] 最小二乘法: a is : 1.3728617616388785 b is : 3.424909795319972 cost is : 39.02051950964002 最小绝对偏离估计: a is : 1.3728617616388785 b is : 3.424909795319972 cost is : 2.647783487811292 最小最大偏离估计: a is : 1.3728617616388785 b is : 3.424909795319972 cost is : 21.373929585192865