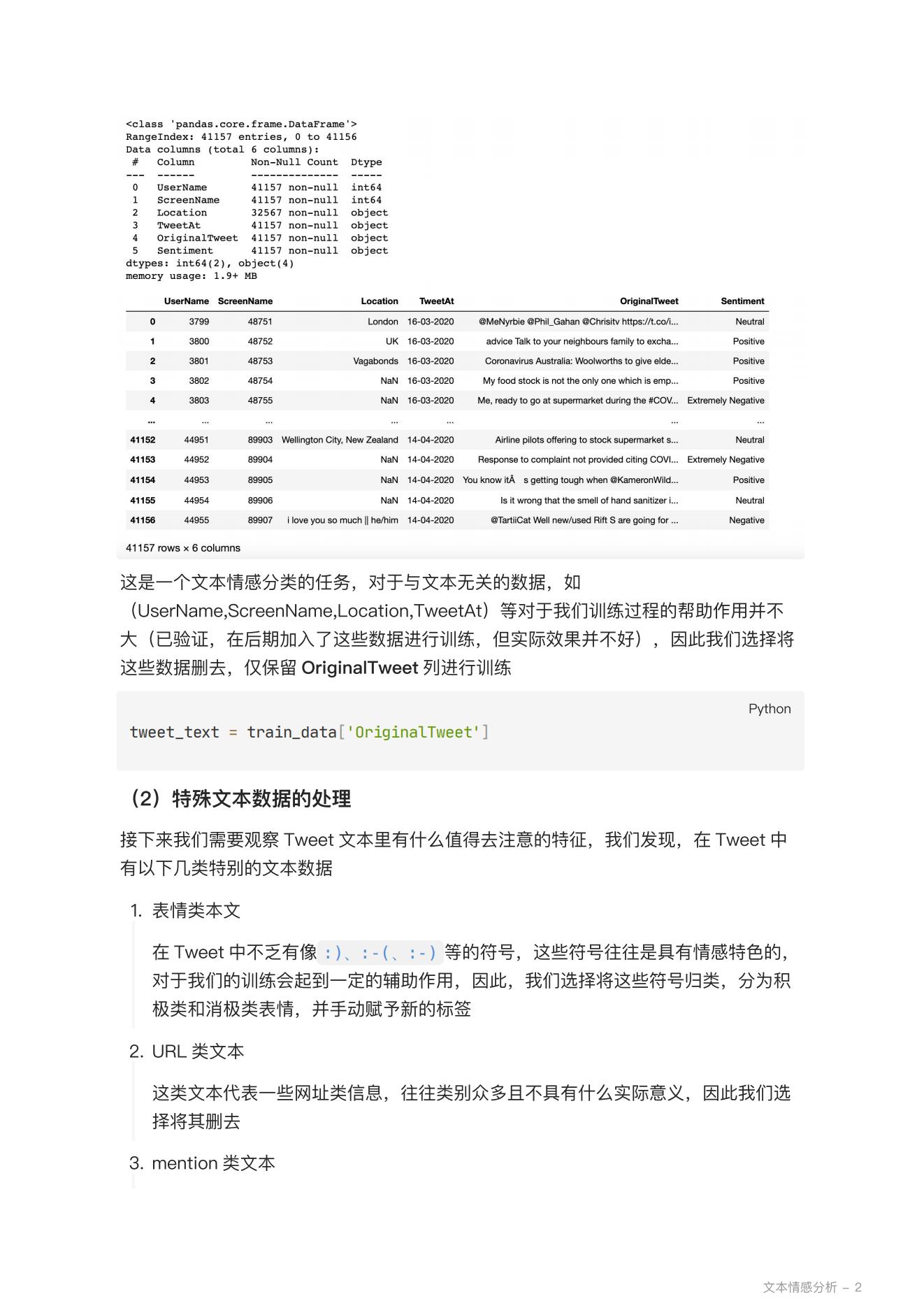
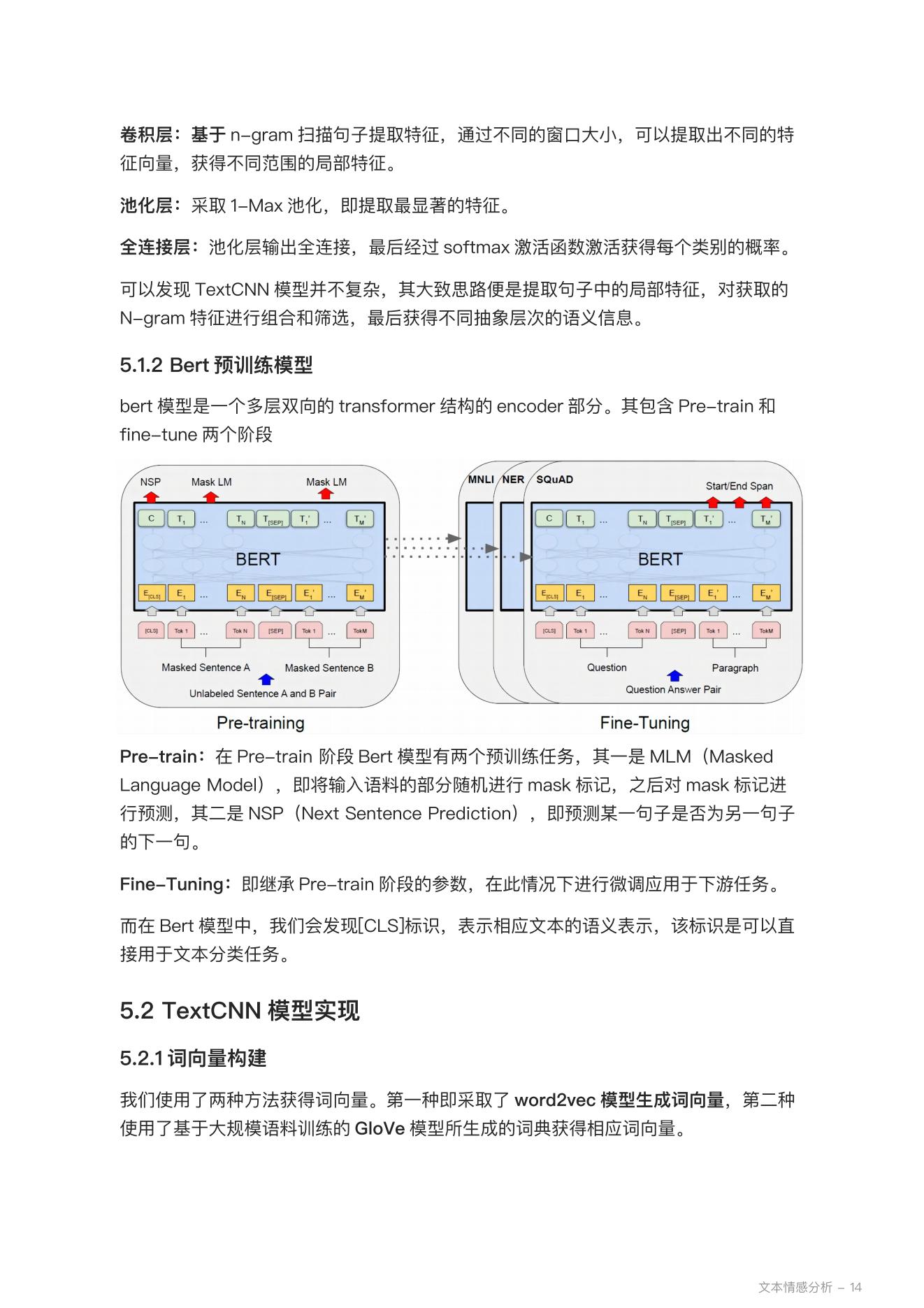
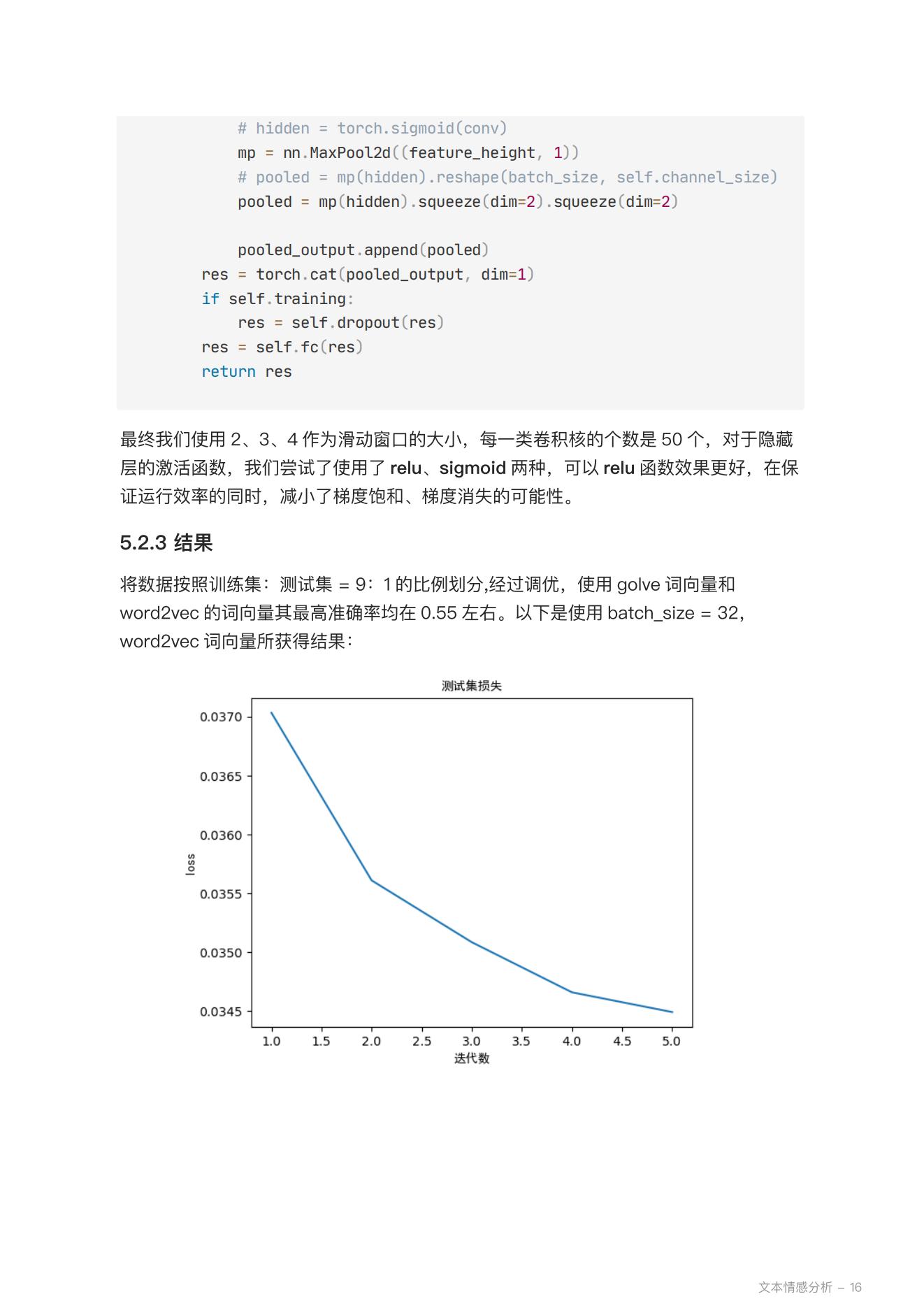
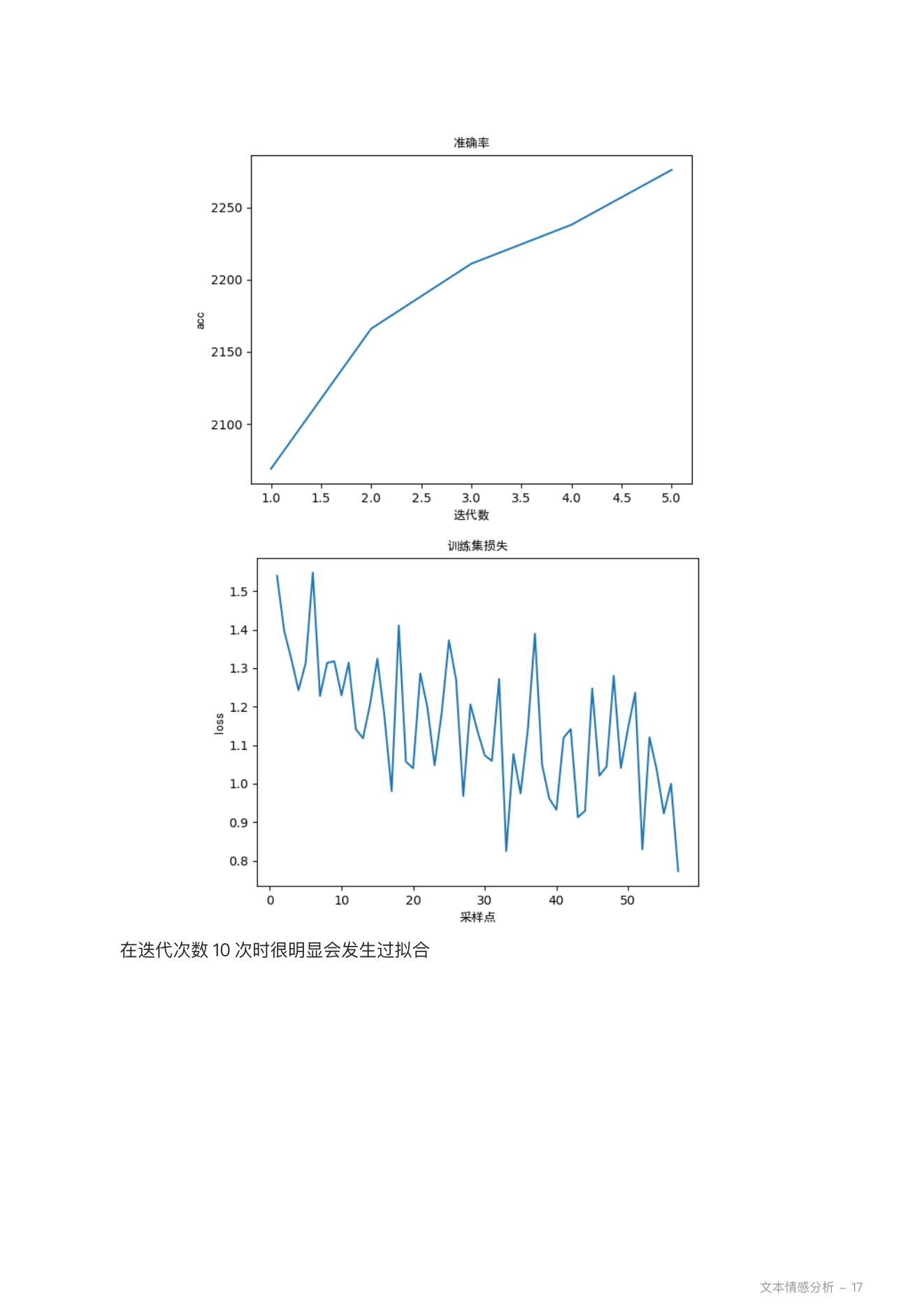
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
| import pickle
import pandas as pd
from keras import Sequential
from keras.layers import Embedding, LSTM, Dropout, Dense
from sklearn.model_selection import train_test_split
import numpy as np
from tensorflow.compat.v2 import keras
from keras.models import load_model
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
vocab_dim = 100
maxlen = 70
batch_size = 32
n_epoch = 4
f = open("dictW.pkl",'rb')
index_dict = pickle.load(f)
word_vectors = pickle.load(f)
n_symbols = len(index_dict) + 1
embedding_weights = np.zeros((n_symbols,vocab_dim))
for w,index in index_dict.items():
embedding_weights[index, :] = word_vectors[w]
def text_to_index_array(p_new_dic=None,p_sen=None):
new_sentences = []
for sen in p_sen:
new_sen = []
for word in sen:
try:
new_sen.append(p_new_dic[word])
except:
new_sen.append(0)
new_sentences.append(new_sen)
return np.array(new_sentences)
train_data = pd.read_csv('./train.csv', encoding='ISO-8859-1')
train_label = train_data['Sentiment']
train_label_New = []
for label in train_label:
labelArray = [0] * 5
if label == "Positive" :
index = 0
elif label == "Negative":
index = 1
elif label == "Neutral" :
index = 2
elif label == "Extremely Positive" :
index = 3
else:
index = 4
labelArray[index] = 1
train_label_New.append(labelArray)
train_label = train_label_New
train_data = np.load("./sentences.npy", allow_pickle=True)
X_train , X_dev , y_train, y_dev = train_test_split(train_data,train_label,test_size=0.1)
X_train_new = text_to_index_array(index_dict,X_train)
X_dev_new = text_to_index_array(index_dict,X_dev)
X_train_new = keras.preprocessing.sequence.pad_sequences(X_train_new, maxlen=maxlen)
X_dev_new = keras.preprocessing.sequence.pad_sequences(X_dev_new, maxlen=maxlen)
y_train_new = np.array(y_train)
y_dev_new = np.array(y_dev)
print("测试集shape:",X_train_new.shape)
print("开发集shape:",X_dev_new.shape)
def train_lstm(p_n_symbols, p_embedding_weights, p_X_train, p_y_train, p_X_test, p_y_test, X_test_l):
print('创建模型...')
model = Sequential()
model.add(Embedding(output_dim=vocab_dim,
input_dim=p_n_symbols,
mask_zero=True,
weights=[p_embedding_weights],
input_length=maxlen ))
model.add(LSTM(units=100,
activation='sigmoid',
inner_activation='hard_sigmoid'))
model.add(Dropout(0.5))
model.add(Dense(units=512,
activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=5,
activation='sigmoid'))
model.summary()
print('编译模型...')
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
print("训练...")
train_history = model.fit(p_X_train, p_y_train, batch_size=batch_size, nb_epoch=n_epoch,
validation_data=(p_X_test, p_y_test))
print("评估...")
score, acc = model.evaluate(p_X_test, p_y_test, batch_size=batch_size)
label = model.predict(p_X_test)
print('Test score:', score)
print('Test accuracy:', acc)
"""保存模型"""
model.save('./model/emotion_model_LSTM2.h5')
print("模型保存成功")
def show_train_history(train_history,train, velidation):
"""
可视化训练过程 对比
:param train_history:
:param train:
:param velidation:
:return:
"""
plt.plot(train_history.history[train])
plt.plot(train_history.history[velidation])
plt.title("Train History")
plt.xlabel('Epoch')
plt.ylabel(train)
plt.legend(['train', 'test'], loc='upper left')
plt.show()
def get_max_index(listRe):
maxProb = 0.0
maxProbIndex = 0
i = 0
for re in listRe:
if re > maxProb:
maxProb = re
maxProbIndex = i
i = i + 1
return maxProbIndex
def prediction(test_data,raw_test_data):
keras.backend.clear_session()
model = load_model('./model/emotion_model_LSTM2.h5',)
label = model.predict(test_data)
file = open('./submission.txt', 'w')
i=0
for re in label:
index = get_max_index(re)
i = i + 1
if index == 0:
file.write("Positive"+'\n')
elif index == 1:
file.write("Negative"+'\n')
elif index == 2:
file.write("Neutral"+'\n')
elif index == 3:
file.write("Extremely Positive"+'\n')
else:
file.write("Extremely Negative"+'\n')
train_lstm(n_symbols, embedding_weights, X_train_new, y_train_new, X_dev_new, y_dev_new, X_dev)
raw_test_data = np.load("./test_sentences1.npy", allow_pickle=True)
test_data = text_to_index_array(index_dict,raw_test_data)
test_data = keras.preprocessing.sequence.pad_sequences(test_data, maxlen=maxlen)
prediction(test_data,raw_test_data)
|