Dataset Quantization
Abstract
现在的SOTA模型往往都是需要通过大量的数据和GPU等硬件训练资源训练得到的,包括LLM和CV。
于是出现了数据蒸馏,旨在合成小规模的数据集.但是这种合成的数据集在新的架构上并没有好的表现.
于是提出了DQ(Dataset Quantization),就是将一个很大的数据集压缩成一些小的子集,然后用这些子集训练神经网络.
特点:
- SOTA的数据集压缩比 compression ratio
- 在unseen network architecture上训练
结果:
通过60%的ImageNet数据集+20%的Alpaca的instruction tuning data训练, 在各种vision tasks上都没有明显的性能下降.
介绍
深度学习网络在CV和NLP领域都表现出色,并且对数据的依赖很高.
奥,我知道了,就是先用自己的3 billion的数据集在模型训练, 然后让训练好的模型在ImageNet-1K上test,得到的就是SOTA模型.
所以就会想, 是不是数据集中的所有数据都是有用的呢?有没有冗余的数据,可以删掉并且不影响下游任务的呢?
下图:虽然显示了经过DQ框架之后确实压缩率很高,尤其是LLM部分,但是同样也没有说结果差了多少,还是说几乎持平?.
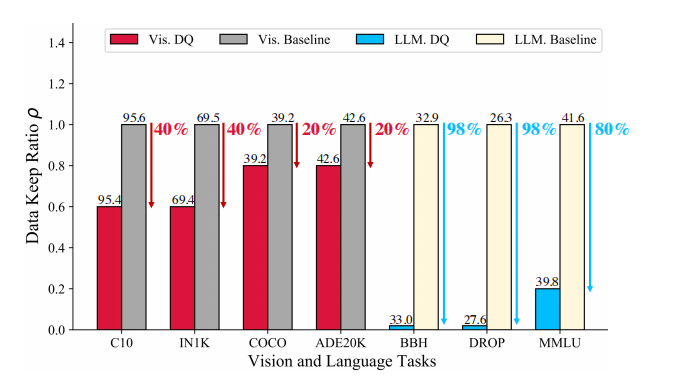
什么是data keep ratio?
data keep ratio就是数据保留比例,就是我压缩之后和原始数据的比例.相当于data compression ratio,就是数据压缩比.
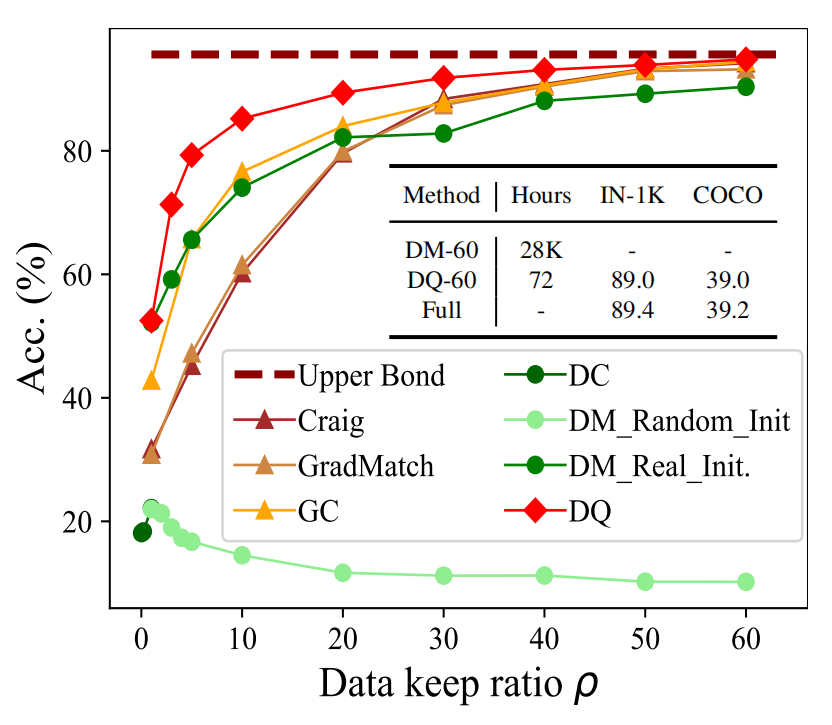
下图2b中当data keep ratio为20%(很低)的时候, synthesized dataset就会丧失diversity~
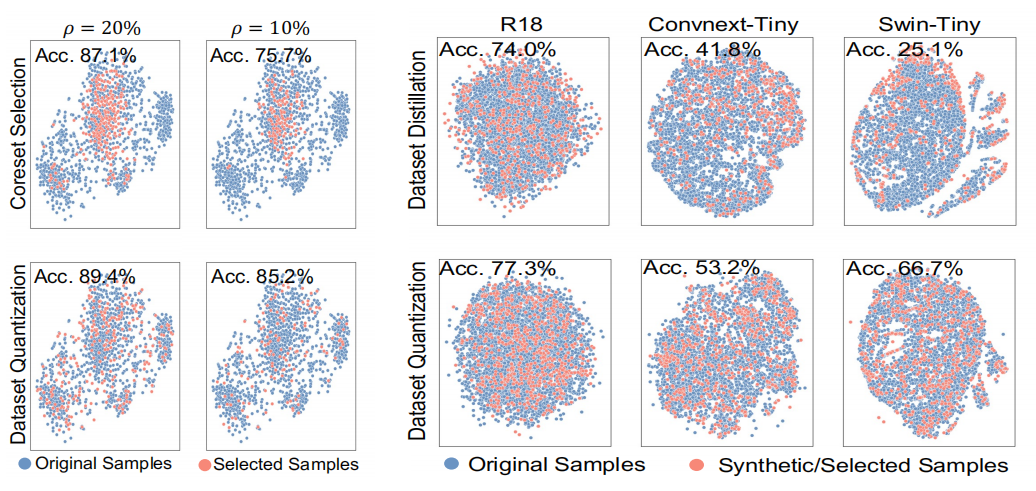
DQ和coreset selection以及dataset distillation相比,可以发现DQ能够顾全大局~所以表现比较好.
没太看懂的这个图的意思是什么:
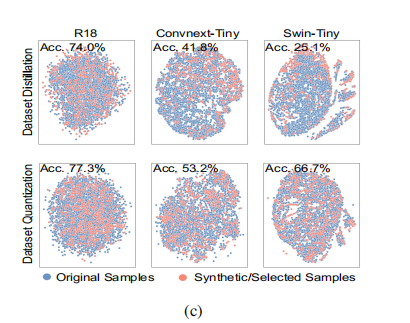

意思就是根据ResNet-18架构得到的合成数据集在Swin-Tiny上的效果很差.
大概的思路是: (粗略地用鼠标画了一个图哈哈)
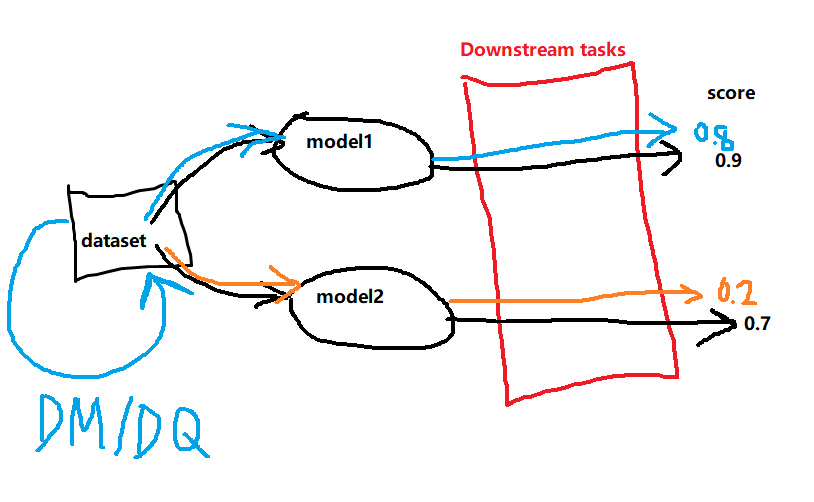
如果是原本的DM(dataset matching)进行数据压缩, 需要大量的计算资源, 比如28000GPU小时才能将IN-1K压缩到60%.
提出的方法:
coreset methods + dataset distillation
具体而言:
- 将数据集划分为不重叠的bins
- 在每个bins里面采样
- 并计算其重要程度
- 训练阶段用重要的patches和预训练好的MAE模型重组数据集
相关工作
Dataset Distillation [数据集蒸馏]
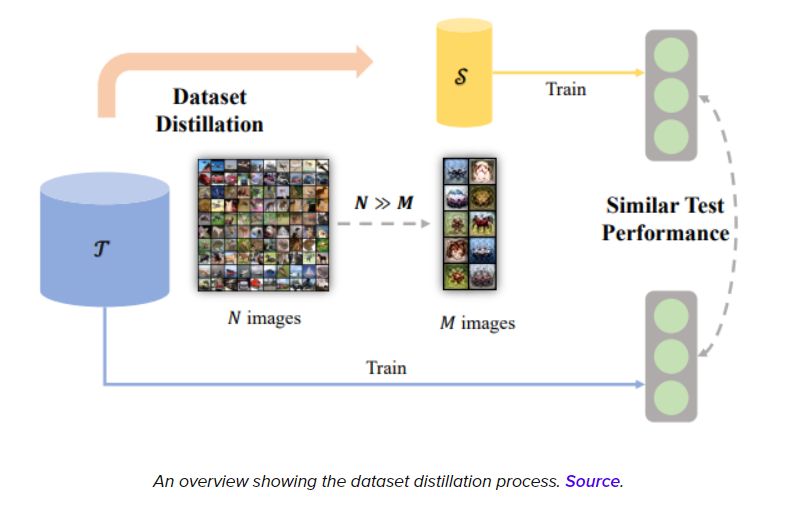
缺点:
- poor-generalizability, 指的是在cross-architecture表现差
- poor scalability,指的是随着data keep ratio的上升, 很快就饱和了,上限不够高
- 需要消耗大量的计算资源
但是上面的缺点, 全部都被coreset methods解决了????
Coreset Methods
就是核心集, 其实就是找到一个子集 , 是representative sampling.
缺点:
- 在low data keep ratio下, 数据的diversity很难保证.
Methods
由于data matching metrics是和网络架构绑定在一起的,所以我们的目标是找到一个对模型架构不敏感的data selection strategy~
Coreset Selection
这个方法虽然解决了DD的缺陷,但是带来了selectioni bias (在density比较高的地方更容易被选中).
我们接下来用theoretical的方法来分析:
我们选择SOTA方法(GraphCut)来分析.
现在有一个数据集D:
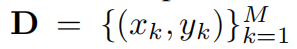
我们默认要从中选出K个样本来组成一个coreset.
前面有提到说先要划分成non-overlapping的bins.在划分好之后,对于每一个bin的更新方法:
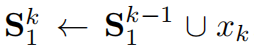
表示对于第1个bin而言,first k-1 sample并上xk得到S1的first k sample.
在初始化好S11之后,如何选择xk就成为了问题的关键. GraphCut采用的是maximize下面的式子(1):
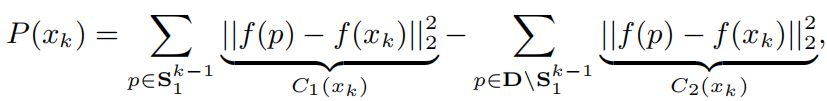
其实一个很简单的思想就是: 让选定的数据集具有更大的diversity.
所以对于xk而言,要求其和Sk-1里面的所有样本差异尽可能大,并且和Sk-1的互斥集差异尽可能小, 得到的xk就是当前要找的那个样本.
但是上面式子的问题在于:
K<<M,即每个bin要选择的样本数远远小于数据总量M.
这将导致C1 << C2, 所以C2就处在了dominant position上, 最后的diversity效果也不理想.
哦,文中有说supposing the average feature at the origin,所以按照下图的意思,就会导致每次选的xk都会在average feature的附近,导致缺少了数据选择的diversity.
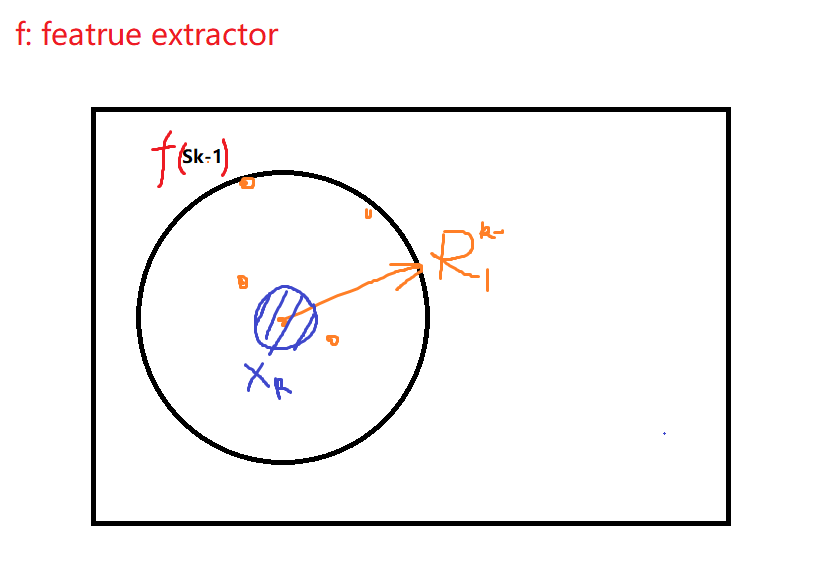
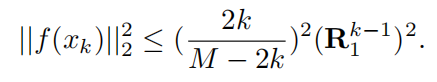
为什么是小于等于?不是要尽可能地扩大差异化吗? 那不是应该大于?
而且由于M>>k,那所有地xk都会接近于范式2的值等于零的情况啊, 对啊, 所以diversity就很差~
由此得出的结论是: coreset selection带来的poor diversity的主要原因是 M>>k.
于是一个idea就是recursively(递归地)进行select. 其实就是S1选好之后, S2从D1中选 :
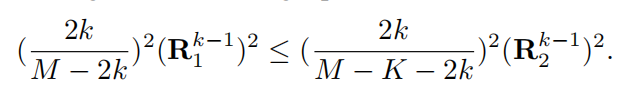
于是上面这个式子(2)中的限制范围被扩大了, 所以xk的选择余地更多了, 这同样意味着diversity变多了.
问题在于, 难道不是先划分好不重叠的bins,再进行select的? 为什么最开始的方法是从整个数据集中选? 而不是从S1的子集中选出first k sample?
对的, 因为这是DQ, 本文要介绍的方法, 不是coreset的做法...
于是有:

这种recursive的方法划分数据集带来的是不一样的diversity level. 很明显, 最开始划分出的S1多样性最差, 越到后面多样性越好?
真的是这样吗? 到后面的R会不会也变小?无所谓啦, R即便变小, 还是不如前面系数中的分母变小带来的影响大~
DQ
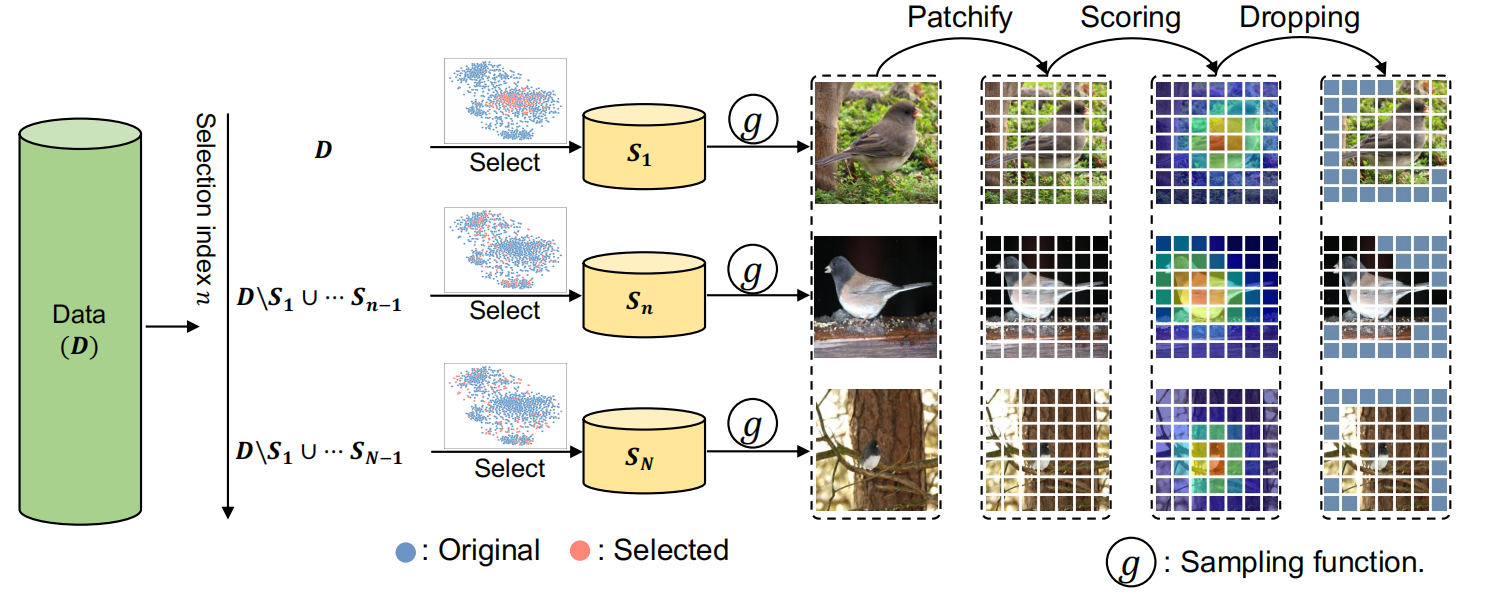
上图就是DQ的主要方法, 其实可以看出, 由于是递归选择的, 所以一开始的选择的时候diveristy最差, S1都选在了一起, 一簇的感觉, 随着n越来越大, 被除去的数据也越来越多, 可以看到当n = N的时候, sample的点几乎遍布整个数据集, 具有很大的diversity
1 Dataset bin generation
原本是最大化这个式子:
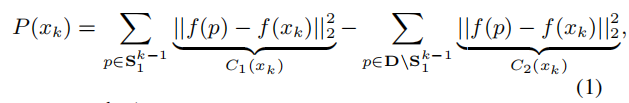
现在是最大化这个式子:
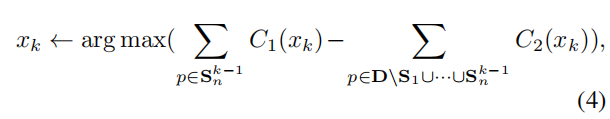
为什么会想到上述递归的选取方法?
就是因为分析了(1)式的等价式子(2):
发现通过递归去除已经选好的S, 会加大bin选取的diversity~
文中也有提到是一个representativeness和diversity之间的一个trade-off. 其实前面也分析过, 对于S1而言, diversity最差, 但是同样也最具有representative, 对于SN而言就是反过来~

总感觉上面的算法写的不对... 好多问题看着...
2 Bin sampling
当划分好bins之后, 就是在每个bin中进行sampling, 然后取个并集, 最后就是synthesized dataset了.
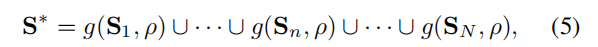
g(S,p)就是一个采样函数, p表示data keep ratio.
除此之外, 我们还对每个样本进行分析(Masked Auto-Encoder → MAE):
- 划分Images为patches
- 计算每个小格的weight
- 设置阈值,丢掉不重要的格子
Experiments
终于到实验部分啦)
在原始数据集为CIFAR-10上, 作者用ResNet-18当作feature extractor , 然后将压缩后的数据在不同的模型(ViT, Swin, ConvNext等)上进行训练.
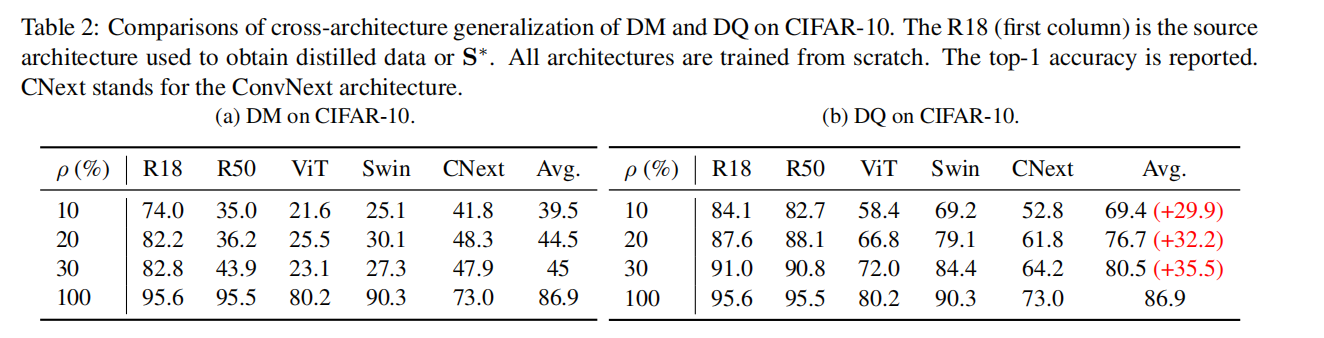
上面的表格可以看出, DM在RN18训练中表现得很好, 但是一旦迁移到别的架构(R50, ViT...), 就会大幅下降. 但是DQ却仍旧能够保证相对很好的效果, 说明DQ的cross architecture的表现很好~
超参数
DQ有两个超参数:
- 是bins的数量N
- patch drop ratio: theta
在较大的data keep ratio的时候, 较大的drop ratio有利于模型的acc.
还有很多对比试验:
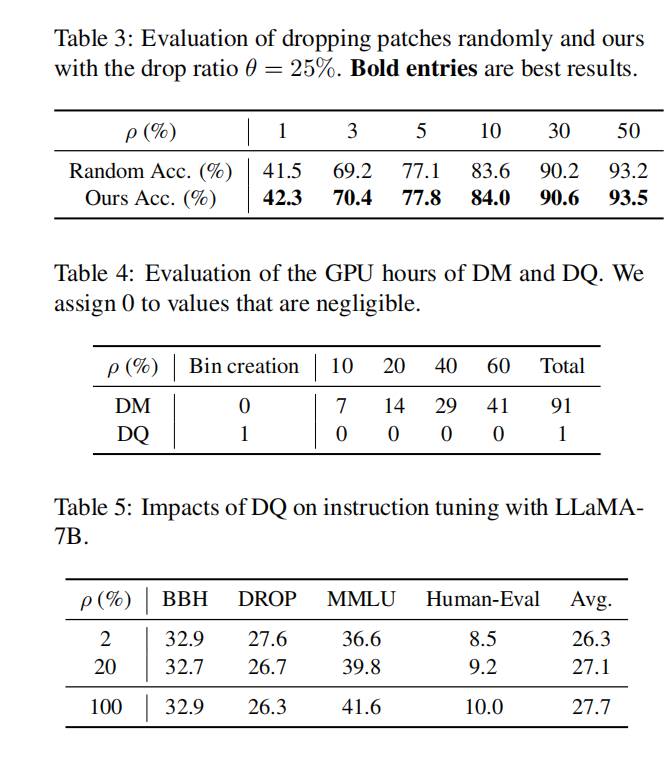
比如到底是随机丢弃, 还是设置一个阈值丢掉weight低的patch, 以及GPU的训练时间等等.
总结
花了四个小时读完了这篇论文, 总之差不多了解了什么是DQ, 以及和coreset, distillation的区别以及具体的理论推导. 感觉理论部分不难, 具有很好的可解释性.
但是文中也说递归也会带来computational cost, 所以说如果一开始就随机划分好N个bins,然后每个bin都具有自己的diversity和representative值, 然后给bin中的每个sample打一个diversity score(其实就是和文中这个样本相距bin中averageR的距离成正比).
为了将每个bin都映射成不同的diversity level(因为这样才能存在既有diversity又有representative的bins了), 可以将最开始随即划分的bins, 根据每个样本的diversity互相交换(因为要保证每个bin的样本数量都是K,是一致的, 所以是"交换",不是"收编")